PDFの表データ→Excel表に変換(半角空白で区切られている場合)
お仕事などでお客さんからPDFで資料が送られてきて、
そのデータを基に仕事を進める際に、そのデータをExcelに写して
作業を進める事は多いのではないでしょうか?
◆PDF表のデータをコピーし、Excelに貼付けたら、
データが半角空白でそれぞれ区切られて表示された
◆PDF表データは1セルも空白が無い状態だ
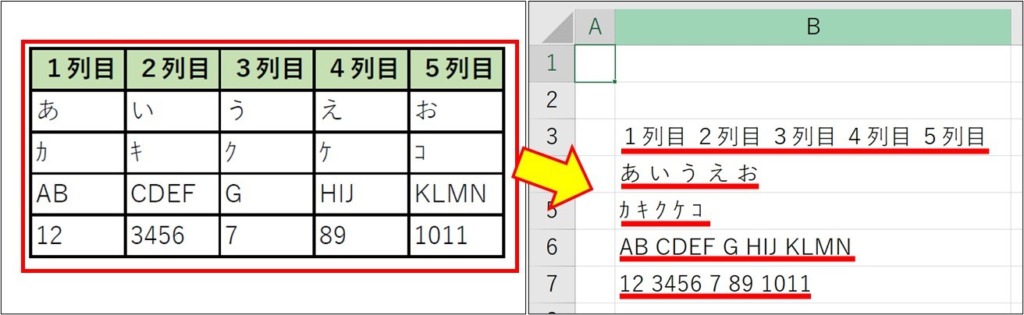
今回は↑の件に当てはまる
【PDFの表データ→Excel表】に転記する方法を記載します。
※お急ぎの方は、記事中腹に変換用の数式が入ったファイルをアップロードしましたので、
そちらをダウンロードして頂き、ご活用ください。
『データが半角空白で区切られている場合』とは具体的には
PDFの表部分をコピーして、Excelに貼り付けると、冒頭の画像のようになる場合です。
また再度注意点ですが、これからご紹介する方法では
表がびっしり1セルも空白が無い場合にのみ、有効です。
この場合は是非とも、下記の方法を参考に解決されたら嬉しいです。
空白がありますと、その部分はうまく表示されませんので、
個別の対応(変換)が必要となります。空白が1~2か所程度ならば対応出来ると思いますが。
※PDF表のデータをコピー&貼付けした際に、データが縦1列に表れてしまう
そんな場合は、別の記事にまとめましたので、下記をご参照いただけると幸いです。

空白で区切られている場合は、あらかじめ準備しておいた数式を使って分離します。
それでは参りましょう。
関数・数式を使ってデータをExcelに一発変換
以下の関数を使います。
■FIND関数
■LEN関数
■MID関数
■LEFT関数
■RIGHT関数
※IFERROR関数 は見た目の問題。ここではおまけみたいな感じです。
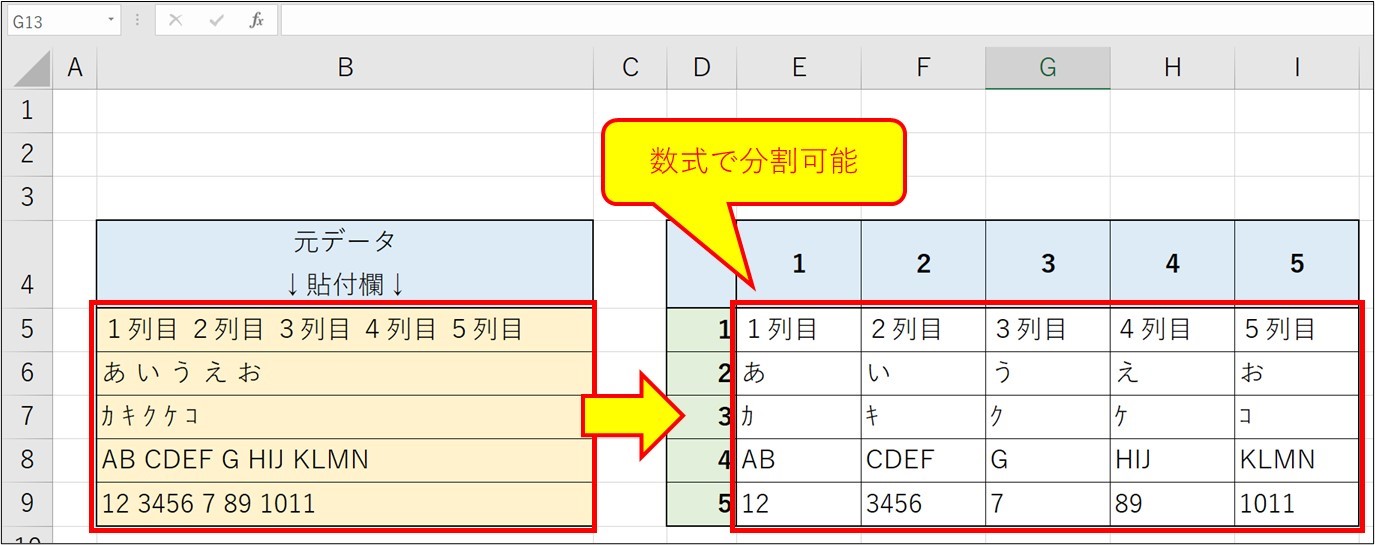
どのように変換するかというと、下のファイルのように、
1列目、2列目、3列目…という具合に関数・数式を入れていき、
とある1列に空白で区切られたPDFの表データを貼付けするだけです。
ファイルを添付しますので、お試ししてみてください。
※UPしているファイルにはPDF表データが「2列x30行」~「10列x30行」分あります。列数に応じてそれぞれのsheetにデータを入れ込んでください。
ファイルをダウンロードするのが、気にかかる方は
下記の要領で、自作で数式を入れてみて下さい。
数式を自作する場合
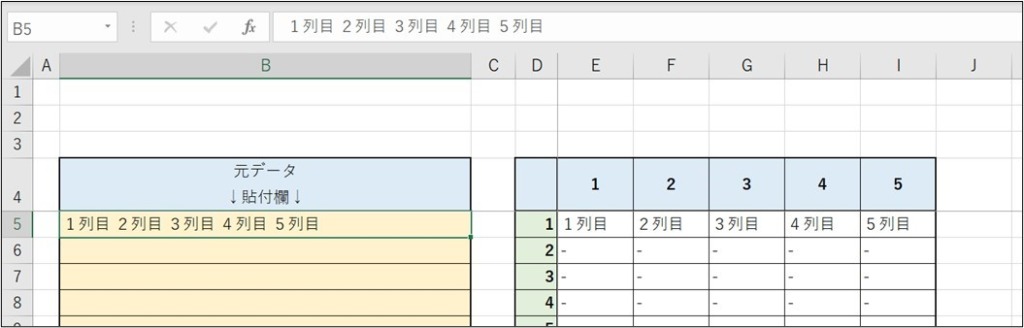
例えば、アップロードしたファイルのように
・【B5】を先頭にPDF表データを貼付けし、
・【E5】を左上の隅として抜き出すデータを入れ込む場合
◆1列目…=IFERROR(MID(B5,1,FIND(” “,B5,1)-1),”-“)
◆2列目…=IFERROR(RIGHT($B5,LEN($B5)-(LEN($E5)+1)),”-“)
◆3列目…
=IFERROR(MID($B5,LEN($E5&$F5)+3,FIND(” “,$B5,(LEN($E5&$F5)+3))-(LEN($E5&$F5)+3)),”-“)
◆4列目…
=IFERROR(MID($B5,LEN($E5&$F5&$G5)+4,FIND(” “,$B5,LEN($E5&$F5&$G5)+4)-(LEN($E5&$F5&$G5)+4)),”-“)
◆最終列…=IFERROR(RIGHT($B5,LEN($B5)-(LEN($E5&$F5&$G5)+3)),”-“)
もしもPDFのデータが6列以上の場合、
もしくは5列未満の場合は、以下に簡単な数式の説明をします。
そちらを参考にして頂けますと幸いですが、
自分でも説明がうまくできていると思えないので、ファイルをご覧頂いた方が早いと思います(笑)
数式の(簡単な)説明
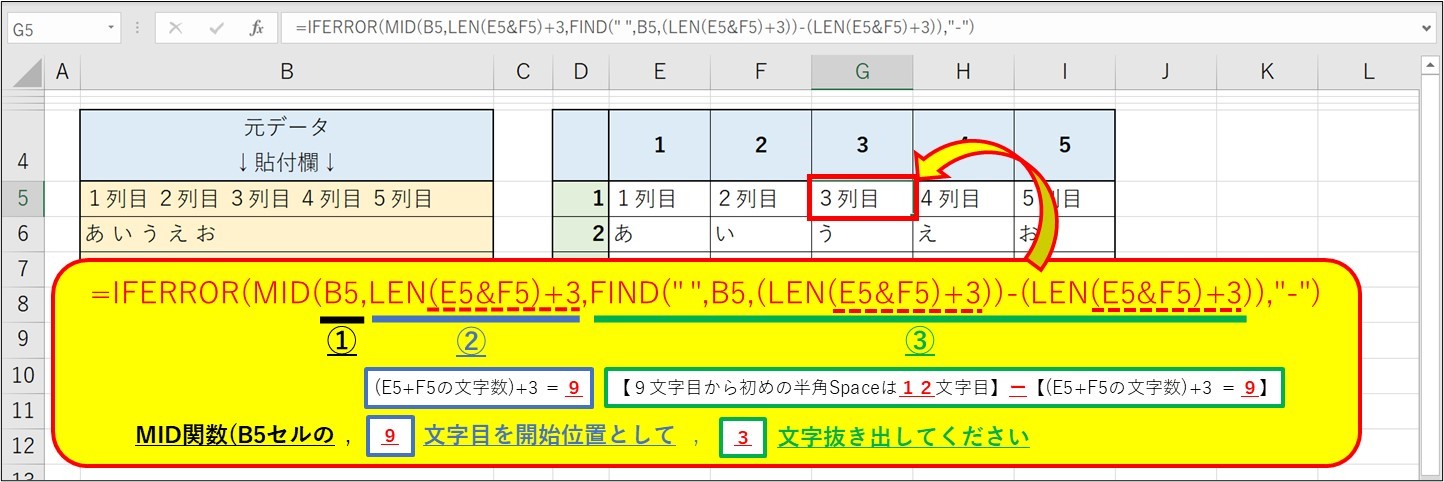
◆1列目に関しては
[ MID( ” PDF元データ ” , 1 , FIND( ” “, ” PDF元データ ” , 1 ) -1)
◆点線部分 [ +3 ] は2列目以降に追加する項目で
2列目= [ +2 ]
3列目= [ +3 ]
4列目= [ +4 ]
5列目= [ +5 ]・・・
と1ずつ足していきます。これは1列分の空白が増える分、
MID関数の開始位置を1文字分遅らせる為です。
◆下線部②、③のLEN関数の部分に関しては
2列目= [ LEN( “1列目 ” ) ]
3列目= [ LEN( “1列目 & 2列目 ” ) ]
4列目= [ LEN( “1列目 & 2列目 & 3列目 ” ) ]
5列目= [ LEN( “1列目 & 2列目 & 3列目 & 4列目 ” ) ]・・・
と列数に応じて増やしていきます。
◆そして最終列は
[ =RIGHT( ” PDF元データ ” , LEN( ” PDF元データ ” ) – (LEN( ” 今までの列 ” ) + ” 最終列 -1“) ]
これで完成です。後はデータを【B2】に張り付けるだけです。
もしも複数行ある場合は、その分だけ下に入れ込んだ数式を伸ばして下さい。
今回、各関数がどのように作用しているか、の細かい解説は抜きにしますが、
つまるところ、MID関数を軸にして、
次の空白までに何文字あるかを、数式で算出した文字数を足し・引き算する形で
該当の箇所の文字列を抜き出している状態です。
いかがでしょうか?
解決出来て、業務の効率化、時短につながれば幸いです。